Embedded Infastructure
- Getting Started
- Project Structure
- Packet Dispatcher
- High Level Overview
- Functions of the Packet Dispatcher
- Helper Macros for Handler Config
- Recommended Usage Pattern
- Embedded Common Libraries
- Unit Testing
Getting Started
How to setup and get started working on the embedded code
STM32CubeMX
This page: the short, concrete workflow for using STM32CubeMX to configure an STM32 project and generate init code without accidentally nuking your work.
Download: https://www.st.com/en/development-tools/stm32cubemx.html
1) What is it
STM32CubeMX is a graphical tool that simplifies the configuration of STM32 products, and generates the corresponding initialization code through a guided step-by-step process.
> st.com
In the embedded subteam, we use STM32 Nucleos to make our robot come to life. We use CubeMX to enable these boards to do what we want by setting the pins on the physical board and generating code that we can use to drive those pins.
2) Starting a (new) project
Once you have successfully installed CubeMX, you can either create or open a project. You will most likely be working with already existing CubeMX projects. You can open any project by finding the .ioc file. This is the configuration file for any CubeMX project.
However, there are some important settings that any project needs.
a. New project
When creating a NEW project make sure you use the board selector and NOT the MCU selector to start your project (given the fact that you will be working with a board). If you don't do this, it will cause problems down the line.
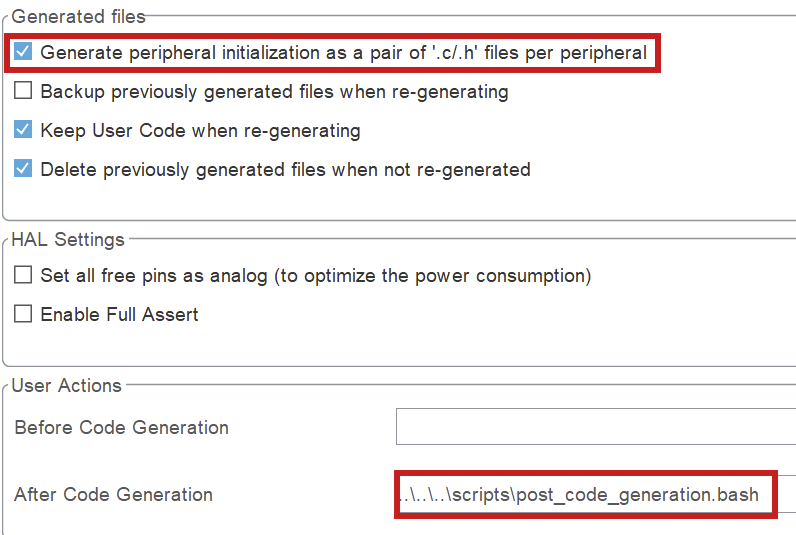
b. Project Settings
Project Manager > Project
Once you have your project open, navigate to the project manager.
- It is important that your project name is "firmware", since this is the name the folder is supposed to have in the embedded structure. (This is platformio configuration related.)
- Do not generate main(). You should only generate a main function to check what is in there and use it as an example, but when you want to build, you can not have a main function in your auto-generated code. It will conflict with your own main function.
- Set the toolchain to Makefile. You should not use another toolchain, because the post code generation script uses information from the Makefile!
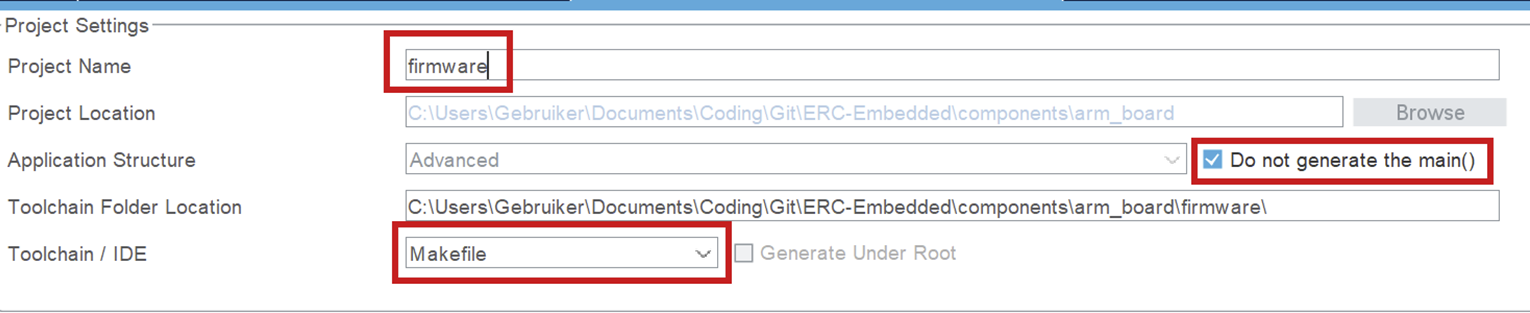
Project Manager > Code Generator
- Click the box to generate separate files per peripheral. Otherwise you will encounter errors surrounding missing libraries when building.
- Set the after code generation script. It can be found in
scripts/post_code_generation.bash. More information in Post-Generation Scripts.
NOTE for Windows users: the post generation script will NOT automatically be ran for you. Instead, you will have to run the script by hand in the git bash terminal.
3) Typical Workflow
a. Configure pins & peripherals
- In Pinout & Configuration: enable the peripherals you need (UART/SPI/I2C/CAN/Timers/ADC/etc.).
- Assign pins and resolve conflicts (CubeMX will warn you).
- Configure DMA + NVIC if needed (especially for high-rate IO or RTOS systems).
b. Set up the clocks
- Go to Clock Configuration and set your clock source (HSI/HSE) and PLL to the target system frequency.
- Verify peripheral clocks (UART baud rates and timer frequencies depend on this).
- If USB is used, make sure USB clock requirements are satisfied (CubeMX will usually flag invalid setups).
c. Code generation
Do not write custom code in CubeMX-generated files.
CubeMX will overwrite generated files during regeneration. Any custom code placed there will be lost, even if it appears to work temporarily.
Rule:
- Generated code is read-only.
- Your code lives outside of it.
What to do instead:
- Put all application logic in your own source files (
src/, modules, drivers, etc.). - Only use generated code as initialization and hardware configuration.
- Call your own code from the appropriate entry points (e.g. after init in
main()).
Bottom line:
If your code depends on surviving a “Generate Code” click, it’s in the wrong place.
d. Generate code, then build & verify
- Open Project Manager and confirm the project type/toolchain and output path are correct.
- Click Generate Code.
- Immediately review changes (e.g.
git diff). If CubeMX changed a lot more than expected, stop and investigate before committing. - Build the firmware and run a basic smoke test (UART prints, LED blink, peripheral init success, etc.)
Git Submodules
On this page
- 1. Why submodules?
- 2. Key concepts
- 3. Cloning a repo with submodules
- 4. Adding ERC-Protobufs as a submodule
- 5. Updating ERC-Protobufs (pinning a new commit)
- 6. Branches, detached HEAD, and what “pinned” means
- 7. Common mistakes
- 8. Command cheat sheet
1) Why submodules?
A git submodule lets one repository “mount” another repository at a specific commit. That sounds fancy, but it’s really just Git saying: “this folder is a separate repo, and we are pinning it to a specific SHA because reproducibility is not optional.”
- should be versioned and reviewed independently,
- must be pinned (reproducible builds, fewer “works on my machine” sightings),
- is shared across multiple firmware/software repositories.
RoboTeam example: ERC-Protobufs can be shared between embedded firmware, tooling, and PC-side code. Pinning ensures everyone generates/uses the same message definitions — which is what prevents “my robot speaks protobuf dialect #3” incidents.
2) Key concepts
Term | What it means | Why care about it? |
|---|---|---|
| A file in the parent repo that stores submodule name/path/URL. | This is what gets committed so everyone else can actually fetch the submodule without guessing. |
“Pinned commit” | The parent repo records a specific commit SHA for the submodule. | Builds are reproducible; updating is an explicit change (and therefore reviewable). |
Detached HEAD | By default, a submodule checks out the exact pinned commit, not a branch. | Normal. It looks scary the first time, but it just means “you’re on a commit, not a branch.” |
| Checks out the submodule commit referenced by the parent repo. | Use after switching branches or pulling changes, because submodules do not magically follow along. |
3) Cloning a repo with submodules
If a repository already uses ERC-Protobufs as a submodule, you must fetch it after cloning. Otherwise Git will politely give you an empty folder and let you discover the problem at build time.
Recommended (one command)
git clone --recurse-submodules <PARENT_REPO_URL>If you already cloned (two commands)
git submodule init
git submodule updateTip: Add --recursive if the submodule itself contains submodules:
git submodule update --init --recursiveSymptom you forgot submodules: build errors like “file not found”, missing generated headers, missing .proto files, or empty directories where ERC-Protobufs should be.
4) Adding ERC-Protobufs as a submodule
Use this when a parent repository needs to include ERC-Protobufs for builds/code generation. This is a dependency decision, not a casual Friday activity.
Step-by-step
- Choose where it should live in your repo, for example:
third_party/ERC-Protobufs(orlibs/ERC-Protobufs). - Add the submodule:
git submodule add <ERC_PROTOBUFS_REPO_URL> third_party/ERC-Protobufs - Commit the changes:
git add .gitmodules third_party/ERC-Protobufs git commit -m "Add ERC-Protobufs as a submodule"
What gets committed? (a.k.a. “what did I just do to the repo”)
.gitmodulesfile (submodule metadata)- a “gitlink” entry at
third_party/ERC-Protobufsthat pins a specific commit SHA
The submodule’s full contents are not copied into the parent repo history. You’re committing a pointer, not a copy.
Protocol for RoboTeam: confirm with your lead whether the submodule path is standardized across repositories (helps tooling and scripts, and prevents everyone inventing thirdparty/ in six different spellings).
5) Updating ERC-Protobufs (pinning a new commit)
Updating a submodule means: “the parent repo now points to a newer commit of ERC-Protobufs”. This should be done intentionally and reviewed because it can change message definitions and compatibility. Treat it like an API bump, not like updating a meme folder.
Update flow (safe + explicit)
- Enter the submodule directory:
cd third_party/ERC-Protobufs - Fetch latest commits:
git fetch --all --tags - Check out the desired commit (or a tag):
git checkout <commit-sha-or-tag> - Go back to the parent repo and commit the updated pin:
cd ../.. git status git add third_party/ERC-Protobufs git commit -m "Bump ERC-Protobufs submodule to <sha-or-tag>"
Optional (if you want the newest remote-tracking commit): inside the parent repo:
git submodule update --remote --mergeThis requires the submodule to have a branch configured; it is less explicit, so use with care (automation is great right up until it updates something you didn’t mean to update).
Do not “fix” submodule issues by deleting the folder. That often creates messy diffs and makes Git sad. Use actual submodule commands instead.
6) Branches, detached HEAD and what “pinned” means
When you run git submodule update, Git checks out the exact commit recorded by the parent repo. This usually results in a detached HEAD state inside the submodule.
This is normal. A consumer repo typically should not make local changes inside the submodule. If you need to change ERC-Protobufs itself, do that in the ERC-Protobufs repository and then bump the pin in the consumer repo. Submodules are for consuming, not freestyle surgery.
How to tell what commit you are pinned to
# From the parent repo root:
git submodule statusHow to see what changed after a submodule bump
# From the parent repo root:
git diff --submodule7) Common mistakes
“Directory is empty / looks uninitialized”
git submodule update --init --recursive“Submodule shows changes but I didn’t touch it”
Often caused by being on the wrong commit, or having local edits in the submodule. Either way, Git is not gaslighting you — something really is different.
cd third_party/ERC-Protobufs
git status
git reset --hard
git clean -fd
cd ../..
git submodule update --init --recursiveWarning: git reset --hard and git clean -fd will delete local submodule changes. Only do this if you are sure you don’t need them (i.e., you didn’t secretly do work inside the submodule and forget).
“I switched branches and submodules are wrong”
git submodule update --init --recursive“I updated the submodule but forgot to commit in the parent repo”
After updating inside the submodule, you must commit the new pin from the parent repo. Otherwise you updated your local checkout and told nobody, which is the Git equivalent of whispering into the void.
git add third_party/ERC-Protobufs
git commit -m "Bump ERC-Protobufs submodule"8) Command cheat sheet
Clone with submodules
git clone --recurse-submodules <repo-url>Initialize/update after cloning
git submodule update --init --recursiveShow pinned commits
git submodule statusAdd ERC-Protobufs
git submodule add <erc-protobufs-url> third_party/ERC-Protobufs
git commit -m "Add ERC-Protobufs submodule"Bump ERC-Protobufs to a specific commit/tag
cd third_party/ERC-Protobufs
git fetch --all --tags
git checkout <sha-or-tag>
cd ../..
git add third_party/ERC-Protobufs
git commit -m "Bump ERC-Protobufs submodule to <sha-or-tag>"Gaslight your boss :D
(If you need help with abusive bosses reach out @mybrosky_nam, I couldnt do anything about it but I'll try to help you so you don't suffer as well ☮️)
Project Structure
How the code is structured and organized
Layout
Code Structure
Architecture (Summary)
Each board’s main.c acts strictly as an orchestrator. It initializes the runtime, creates tasks, and delegates all functional behavior to component modules.
Core Design Contract
The repository enforces a strict separation between entrypoints and components:
src/<board>/main.cdefines the process entrypoint for each board target.components/common/*contains reusable logic shared across multiple boards.components/<board>/*contains board-specific functionality.components/<board>/firmware/*contains generated or vendor-provided firmware and MCU integration code.
Primary Rule
main.cmust not contain domain logic. It is responsible only for system wiring and task startup.- Albert Einstein
Repository Layout
erc/
├─ src/
│ ├─ arm_board/main.c
│ ├─ driving_board/main.c
│ ├─ sensor_board/main.c
│ ├─ network_board/main.c
│ └─ debugging_board/main.c
│
├─ components/
│ ├─ common/ # Shared modules across boards
│ ├─ arm_board/ # Arm board-specific modules
│ ├─ driving_board/ # Driving board-specific modules
│ ├─ sensor_board/ # Sensor board-specific modules
│ ├─ network_board/ # Network board-specific modules
│ └─ debugging_board/ # Debugging board-specific modules
│
├─ test/
│ ├─ common/
│ ├─ arm_board/
│ ├─ driving_board/
│ ├─ sensor_board/
│ └─ debugging_board/
│
├─ scripts/ # Utility scripts (codegen, post-processing)
└─ platformio.ini # Build environments and board filtersEntrypoint Responsibilities (src/<board>/main.c)
The main.c file is intentionally minimal and should perform only the following:
- Execute mandatory low-level initialization
(HAL, clock, cache, MPU, RTOS initialization as required) - Initialize infrastructure dependencies
(GPIO, UART, timers, networking wrappers, etc.) - Create one or more RTOS tasks
- Start the scheduler/kernel
- Delegate all functional behavior to components
What Must NOT Be Implemented in main.c
The following must never reside in main.c:
- Sensor processing algorithms
- Business or control logic
- Packet parsing or dispatch policy
- Device-specific runtime behavior beyond initialization
- Long-running loops implementing application logic
If logic grows beyond simple initialization or task creation, it must be moved into a component module and invoked from a task.
Component Responsibilities (components/*)
All functional behavior belongs in components. Tasks must delegate to components rather than implementing logic inline.
Examples
Execution Model
The execution flow for each board follows a consistent structure:
main.c
→ platform/runtime initialization
→ create RTOS task(s)
→ each task calls component APIs
→ component modules execute all functional logicThis ensures that:
main.cremains stable and minimal- behavior is modular and testable
- functionality is reusable across boards
Post-Generation Scripts
Introduction
We use one post code generation script. We do this because we do not want to write code inside the auto-generated code, and this helps with that. If you are on Linux or (possibly, untested but likely) mac, you can refer to the script in the cubeMX software by going into Project Manager -> Code Generator -> User Actions -> After Code Generation. If you are not on a UNIX based system you have to run it every time after generating code manually from the folder where the file is located. The file is located under scripts and is called post_code_generation.bash. For mac, the script is called post_code_generator_mac.bash, because there are some small formatting changes, more explained in Mac Changes.
Functions
The script has 4 different functions
Renaming main files
It starts by renaming all main.h and main.c files that are in components. It also saved all boards that have main.c files, because those are the newly generated boards. This way you don't do certain actions on the files twice, if you would run the script again.
while IFS= read -r FILE; do
# Extract the basename (filename without path)
base="$(basename "$FILE")"
if [[ "$base" == "main.c" ]]; then
subdir="${FILE#"$BASE"/}" # Path from the board dir
main_dir="${subdir%%/*}" # The board dir
GENERATED_BOARDS+=("$main_dir") # Gets all boards that are generated again, and thus have a main
dir=$(dirname "$FILE") # Get directory of the file
mv "$FILE" "$dir/cubemx_main.c"
echo "Renamed $FILE to $dir/cubemx_main.c"
fi
if [[ "$base" == "main.h" ]]; then
dir=$(dirname "$FILE") # Get directory of the file
mv "$FILE" "$dir/cubemx_main.h"
echo "Renamed $FILE to $dir/cubemx_main.h"
fi
done < <(find "$BASE" -type f)Adding firmware definitions
Certain constants might have to be set in the main.h files from cubemx. This happens most likely because of the order in which the files are build, but I am not totally sure. However, if you do need to have some constants set in the main.h file, you can at them to any file in the folder called "firmware_definitions" in the common folder of components. This second code block adds it to the .h file.
find "$BASE" -type d -name firmware_definitions | while read -r FW_DIR; do
BOARD_DIR_PATH="$(dirname "$FW_DIR")"
BOARD_DIR="${BOARD_DIR_PATH#"$BASE"/}"
if printf '%s\n' "$COMMON_COMPONENT" "${GENERATED_BOARDS[@]}" | grep -Fx "$BOARD_DIR" > /dev/null; then
BOARD_DIR_PATHS=("$BOARD_DIR_PATH")
if [[ "$BOARD_DIR" == "$COMMON_COMPONENT" ]]; then
BOARD_DIR_PATHS=(${GENERATED_BOARDS[@]/#/"$BASE"/})
fi
for BOARD_DIR_PATH in "${BOARD_DIR_PATHS[@]}"; do
CUBEMX_FILE="$BOARD_DIR_PATH/firmware/Core/Inc/cubemx_main.h"
# Skip if cubemx file does not exist
[[ -f "$CUBEMX_FILE" ]] || continue
echo "Appending firmware_definitions to: $CUBEMX_FILE"
TMP_FILE="$(mktemp)"
head -n -1 "$CUBEMX_FILE" >> "$TMP_FILE"
echo -e "\n/* ---- START firmware_definitions ---- */\n" >> "$TMP_FILE"
find "$FW_DIR" -type f -exec cat {} \; >> "$TMP_FILE"
echo -e "\n/* ---- END firmware_definitions ---- */\n" >> "$TMP_FILE"
tail -n -1 "$CUBEMX_FILE" >> "$TMP_FILE"
# 3) Replace original file
mv "$TMP_FILE" "$CUBEMX_FILE"
done
fi
doneAdding static wrappers
Some functions generated by cubemx you do need, but they are static so you cannot use them outside of the main file. To still be able to do that, the script adds wrappers for those files.
find "$BASE" -type f -name "cubemx_main.c" | while read -r FILE; do
subdir="${FILE#"$BASE"/}" # Path from the board dir
BOARD_DIR="${subdir%%/*}" # The board dir
if printf '%s\n' "${GENERATED_BOARDS[@]}" | grep -Fx "$BOARD_DIR" > /dev/null; then
TMP_FILE="$(mktemp)"
echo "READING $FILE"
while read -r line; do
echo "$line" >> "$TMP_FILE"
if [[ "$line" =~ ^[[:space:]]*static[[:space:]]+[a-zA-Z_][a-zA-Z0-9_]*[[:space:]]+[a-zA-Z_][a-zA-Z0-9_]*\([^\)]*\)\;[[:space:]]*$ ]]; then # Remove 'static' and trailing ';'
echo "Static function found: $line"
proto=$(echo "$line" | sed -E 's/^[[:space:]]*static[[:space:]]+//; s/;[[:space:]]*$//')
# Extract function name
name=$(echo "$proto" | sed -E 's/.*[[:space:]]+([a-zA-Z_][a-zA-Z0-9_]*)\(.*/\1/')
# Extract return type
ret=$(echo "$proto" | sed -E "s/[[:space:]]+$name\(.*//")
# Extract argument list
args=$(echo "$proto" | sed -E "s/.*$name\((.*)\)/\1/")
# Build argument names (remove types)
call_args=$(echo "$args" | sed -E 's/[a-zA-Z_][a-zA-Z0-9_]*[[:space:]]+//g')
if [[ "$call_args" == "void" ]]; then
call_args=""
fi
echo "$ret ${name}_wrapper($args) {" >> "$TMP_FILE"
if [[ "$ret" == "void" ]]; then
echo " $name($call_args);" >> "$TMP_FILE"
else
echo " return $name($call_args);" >> "$TMP_FILE"
fi
echo "}" >> "$TMP_FILE"
echo >> "$TMP_FILE"
echo "added wrapper for static function ${name} in ${FILE}"
fi
done < "$FILE"
mv "$TMP_FILE" "$FILE"
fi
doneChanging the includes
Because of the name change from main.c/h, to cubemx_main.c/h, the includes are now wrong. This last code block changes all the includes to the right name.
while IFS= read -r FILE; do
subdir="${FILE#"$BASE"/}" # Path from the board dir
BOARD_DIR="${subdir%%/*}" # The board dir
if printf '%s\n' "${GENERATED_BOARDS[@]}" | grep -Fx "$BOARD_DIR" > /dev/null; then
sed -i 's/#include "main.h"/#include "cubemx_main.h"/g' "$FILE"
echo "Updated include in $FILE"
fi
done < <(grep -rl '#include "main.h"' ../components/)MAC Changes
1) Added #! /usr/bin/env bash in the first line
2) changed sed -i 's/#include "main.h"/#include "cubemx_main.h"/g' "$FILE"
to sed -i '' 's/#include "main.h"/#include "cubemx_main.h"/g' "$FILE" because mac uses a different version of sed.
Simple PIOC
Introduction
This Python script processes a custom PlatformIO configuration file (platformio.pioc) and generates a standard platformio.ini file.
It extends PlatformIO’s configuration capabilities by:
- Supporting dynamic include paths using glob patterns
- Extracting C preprocessor defines from board-specific Makefiles
- Expanding custom syntax into valid
build_flags - Resolving absolute paths.
Key Features
Custom build_flags Processing
Supports two types of entries:
- +<pattern>: Include directories
- -<pattern>: Exclude directories
- Other entries are treated as standard compiler flags
Include Path Resolution
Glob patterns are expanded into directory paths using recursive search.
Board-specific C Defines
Defines are extracted from:
components/<board>/firmware/MakefileThe script looks for a C_DEFS section and includes all compiler defines.
This is done, because cubeMX generates important definitions in the auto-generated makefile. These are not used if we don't copy them to the .ini file.
Environment Detection
[env:my_board]This determines which board folder is used.
Get Absolute Path
For some functions, like nanopb, you might need the absolute path. There is no way to get in the default platformio.ini file, so that would mean that you would have to hard code it. We do not want that, so we have a placeholder for an absolute path.
The placeholder:
${{project_absolute_path}}$is replaced with the absolute path of the project.
Workflow
- Read
platformio.pioc - Detect environment
- Parse
build_flags - Resolve glob patterns
- Extract C defines
- Write
platformio.ini - Replace placeholders
Example Input
[env:my_board]
build_flags =
+<lib/**>
-<lib/exclude/**>
-DDEBUGExample Output
[env:my_board]
build_flags =
-I lib/module1
-I lib/module2
-DDEBUG
-DDEFINE_FROM_MAKEFILE.pioc file
Introduction
The platformio.pioc file is the central configurationhere file used to define build environments, dependencies, compiler flags, and project structure. It uses a format with sections and key-value pairs. It is similar to platformio.ini, which is actually used by platformio, but has some changes to use it easily with our project. For more information, read Simple PIOC.
File Structure
The configuration is divided into sections such as [platformio], [env], and environment-specific sections like [env:network_board].
Core Sections
[platformio]
Defines global project settings.
default_envs: Default environment(s) to build.src_dir: Source directory.lib_dir: Library directory.
[extra]
Custom user-defined variables for reuse.
[env]
Base configuration shared across all environments.
Environment Sections
Each [env:<name>] defines a specific build target. These inherit from [env].
Custom Enhancements
1. Glob Patterns in build_flags
Unlike standard PlatformIO, this configuration allows glob-style include/exclude patterns directly in build_flags using +<...> and -<...> syntax.
build_flags=
+<components/network_board/**>
-<components/network_board/firmware/Drivers/**>This enables fine-grained control over which directories are included in compilation.
2. Absolute Path Variable
The variable ${{project_absolute_path}}$ expands to the absolute path of the project root.
custom_nanopb_project_dir = ${{project_absolute_path}}$/ERC-ProtobufsSource Filtering
build_src_filter defines which source files are compiled. It supports inclusion (+) and exclusion (-) rules.
+<src/${this.__env__}/**/*.c>
-<components/${this.__env__}/firmware/Drivers/*>Variable Substitution
${extra.common_lib_deps}: Reference shared variables.${this.__env__}: Current environment name.
Library Dependencies
External libraries can be defined using Git URLs or registry references.
lib_deps = https://github.com/nanopb/nanopb.git#commitCompiler and Linker Flags
Standard compiler flags are also supported alongside glob patterns.
-mthumb
-mfpu=fpv4-sp-d16
-D CONFIG_LOG_LEVEL=LOG_INFOExample Configuration
[env:network_board]
board = nucleo_h753zi
build_flags=
+<components/network_board/**>
-<components/network_board/firmware/Drivers/**>
-mthumb
-D CONFIG_LOG_LEVEL=LOG_INFOCompilation
To use the file, you have to convert it to a platformio.ini file. You can do that by running
python3 simple_pioc.pyExtra information
If more information is needed, look at the documentation specifically for platformio.ini files. You can find it here.
Packet Dispatcher
High Level Overview
This Page
Purpose
The packet dispatcher is used to decode protobuf frames.
Application code usually wants:
- strongly typed decoded payloads
- one handler per packet type
- decoupling between input reception and packet processing
This module solves that by:
- receiving a raw protobuf
receive_frame - decoding it into
PBEnvelope - determining
which_payload - finding the corresponding handler
- copying the decoded payload into that handler’s (freeRTOS) queue
- letting a dedicated task call callback for this handler
In short, each packet type gets its own handler callback, queue and task. That makes the system modular and easy to extend, at least conceptually. So the module acts as a bridge between transport-level bytes and application-level packet handler.
In practical terms, it is a decode-and-dispatch layer between an input source that receives raw bytes and a set of application handlers that want already-decoded payloads
The implementation has some assumptions and hazards that absolutely need to be understood before you start messing with its internal structure.
High-level design
The design has three major parts:
- Global handler registry
The global handler registry contains an array of packet handler tasks (see packet_handler_config_t ). A packet handler task configures (amongst other things) the callback function for a certain type of packet.
The array of configs is given by the caller at initialization time. This array is stored globally and used by dispatch logic for packet type lookup.
What we call a packet is a raw protobuf.
What we call a handler is a (configuration of a) callback function for a specific protobuf/packet.
- One queue & task per packet type
The dispatcher takes each handler configuration and creates 1 FreeRTOS queue and 1 FreeRTOS task. When receiving messages, the dispatcher enqueues decoded payloads into the corresponding queue. The corresponding task blocks that queue and calls the handler callback (which saved in the registry).
The task takes the correspoding payload out of the queue and calls the specified handler/callback function. By corresponding we mean that each type of packet has their own queue.
NOTE on handler task lifecycles
Each handler task is intended to live forever.
A task is responsible for passing a specific packet type from the corresponding queue to the correct callback. As stated above, a handler task gets created by the dispatcher according to the configuration (see packet_handler_config_t ) done by the caller when initializing the dispatcher.
Lifecycle
- Created by
PacketHandlerStart()
As part of PacketDispatcherInit(). - Validate configuration
Task_name, handler and queue need to be present for it to work. These params are set in packet_handler_config_t. If you use the macros, this should be fine. - Allocate local packet buffer
- Block forever on queue receive
So, when we receive a packet in the corresponding queue, we wait for it to be handled. - Process packets as they arrive
The processing is done by the callback specified in the handler.
Terminates only if...
- config is invalid
- queue is null
- heap allocation fails for packet buffer
In those cases it deletes itself.
At the moment, there is no restart or supervision mechanism in this module!
External dependencies
This is not a standalone module. It sits in the middle of RTOS tasking, protobuf decoding, and transport reception.
This module depends on:
specifically used pieces | |
FreeRTOS |
|
nanopb / protobuf decoding |
|
|
|
|
|
Functions of the Packet Dispatcher
Public API
The following functions are available for the boards to use outside of the library.
The public API consists of: packet_handler_t, packet_handler_config_t, PacketDispatcherInit(...), DispatchPacket()
There are also stack depth macros: PACKET_HANDLER_TASK_STACK_DEPTH_DEFAULT, PACKET_DISPATCHER_TASK_STACK_DEPTH
1) Stack depth macros
NOTE: PACKET_DISPATCHER_TASK_STACK_DEPTH is currently defined but not actually used in the provided implementation!
#define PACKET_HANDLER_TASK_STACK_DEPTH_DEFAULT ((configSTACK_DEPTH_TYPE)512U)
#define PACKET_DISPATCHER_TASK_STACK_DEPTH ((configSTACK_DEPTH_TYPE)1024U)2) packet_handler_t (callback)
typedef result_t (*packet_handler_t)(void* buffer);This type represents the callback function invoked by a handler task when a packet of its type is received.
Parameters
buffer
Pointer to the decoded packet payload copied from the queue. The actual type of buffer depends on the registered packet_type in the config for the handler (see packet_handler_config_t).
For example, if a handler is registered for one specific protobuf payload type, the handler should cast buffer to the corresponding generated struct type.
Example
static result_t Callback_ArmBoardControlSignals(void *buffer) {
ArmBoardControlSignals* pckt = (ArmBoardControlSignals *)buffer;
}Note on buffer typecasting
The callback receives only a raw void *. That means type safety is entirely dependent on correct configuration!
packet_typemust match the actual protobuf payload memberitem_sizemust match the size of that decoded payload type- handler must cast
bufferto the correct struct type
If any of those mismatch, the code may compile while quietly doing something stupid (and it will be your fault :D).
Return value
Returns result_t. The handler task logs a warning if the return value is not RESULT_OK.
3) packet_handler_config_t (struct)
NOTE: there exist macros to make the configuration easier! See: Helper Macros for Static Handler Config
typedef struct {
packet_handler_t handler;
const char* task_name;
pb_size_t packet_type;
UBaseType_t task_priority;
configSTACK_DEPTH_TYPE task_stack_depth;
size_t item_size;
UBaseType_t queue_length;
uint8_t* queue_buffer;
StaticQueue_t queue_struct;
QueueHandle_t queue;
} packet_handler_config_t;Purpose
Describes one packet type and the task/queue resources needed to process it. Each entry in the handler config array (passed to PacketDispatcherInit(...)) corresponds to one routed packet type!
Fields
handler
Callback invoked when a packet of this type is received. Must not beNULL.task_name
Name used when creating the FreeRTOS task. Must not beNULL.packet_type
The protobuf discriminator value to match againstDecodingEnvelopeCurrent.which_payload, which is the routing key.task_priority
Priority of the FreeRTOS handler task. If set to zero, that is still a valid FreeRTOS priority value. There is no separate “unset” semantic here.task_stack_depth
Stack depth for the handler task.
If<= 0, the implementation replaces it with:PACKET_HANDLER_TASK_STACK_DEPTH_DEFAULT. Since this type is typically unsigned, the<= 0check effectively means “zero” in practice.item_size
Size of one queued item.
This must match the size of the decoded payload type copied into the queue.
queue_length
Number of items the queue can hold.queue_buffer
Backing storage for static queue data.
Must be large enough forqueue_length * item_sizequeue_struct
Static queue control structure used internally byxQueueCreateStatic(). Caller provides storage but should not manually initialize runtime content.queue
Queue handle written internally during initialization.
Caller should not pre-fill it!
4) PacketDispatcherInit(...)
result_t PacketDispatcherInit(packet_handler_config_t* handlers,
size_t handler_count);Initializes the dispatcher by...
- storing the handler registry
- creating one queue and one task per handler entry
Parameters
handlers
Pointer to an array of handler configurations (see above: packet_handler_config_t). The implementation stores a global pointer to it and passes individual entries to tasks.handler_count
Number of entries in the array.
IMPORTANT: The handlers array must remain valid for the full lifetime of the system. Do NOT allocate this array on a temporary stack frame unless you are into being abused by segfaults :)
5) DispatchPacket(...)
void DispatchPacket(receive_frame* incoming_packet);Decodes one incoming raw frame and routes its decoded payload to the appropriate handler queue.
Internal functioning
- validates basic frame properties
- creates a nanopb input stream from the raw bytes
- decodes into the global static
DecodingEnvelopeCurrent - scans the registered handler list
- finds the first handler whose
packet_typematcheswhich_payload - sends
DecodingEnvelopeCurrent.payloadto that handler’s queue - returns
If no matching handler is found, it logs a warning. If decode fails, it logs an error.
NOTE: This function returns void, so dispatch failure is only observable through logs.
Parameters
incoming_packet
Pointer to a transport frame containingpayload,lenof the incoming packet.
Internal (private) task model
PacketHandlerTask()
Also see note on handler task lifecycles !
Each handler config gets its own task (and corresponding queue, remember ladies?) running this loop:
- validate config and resources
- allocate one packet buffer using
malloc(conf->item_size) - block forever on
xQueueReceive() - when a packet arrives:
- call
conf->handler(packet_buffer) - log if handler returns error
- call
Purpose of per-task buffer
The queue copies incoming items into the task’s local packet_buffer. That means the handler callback receives a stable task-local buffer for the duration of the callback. The callback does not receive a pointer directly into the global decode object.
The task allocates its buffer dynamically with malloc() once at startup and never frees it, because the task is intended to live forever.
Macros
There exist macros to make the configuration of a handler easier! See: Helper Macros for Static Handler Config.
Helper Macros for Handler Config
Purpose
To reduce repetitive boilerplate when defining packet handlers, the module also provides a set of helper macros in packet_dispatcher_macros.h.
These macros generate:
- a statically allocated queue buffer
- a fully initialized
packet_handler_config_t
They are especially useful because they automatically derive the correct queue item size from the selected PBEnvelope payload member, which helps avoid one of the easiest mistakes in this module: mismatching item_size with the actual decoded protobuf payload type.
Why these macros are useful
Without these macros, every handler config has to manually specify:
- queue storage buffer
- queue length
- item size
- task name
- default priority
- default stack depth
- queue initialization fields
That is tedious and error-prone.
I) They derive item_size automatically
Each macro uses: sizeof(((PBEnvelope*)0)->payload.payload_member) to compute the exact size of the selected envelope payload member at compile time. This removes the need to manually write .item_size = sizeof(MyPayloadType) and reduces the chance of queue item size mismatches.
II) They allocate queue storage automatically
Each macro also declares:
static uint8_t name##_queue_buffer[...];with the correct total size based on:
- payload member size
- selected queue length
So the queue backing storage is generated alongside the config object.
Important consequence of these macros
These macros define static objects.
That means each use creates:
- a static queue buffer
- a static
packet_handler_config_t
This is generally what you want for a dispatcher configuration that should live for the full lifetime of the system.
It also means:
- they should normally be used at file scope
- using the same
nametwice in one translation unit will cause symbol redefinition - they are not runtime factory macros, they are compile-time object definition helpers
Shared Functionality
For all of these macros, the generated config uses:
#define PACKET_HANDLER_CONFIG_STATIC(name, packet_tag, payload_member_size, handler_fn)
.handler = (handler_fn)
.task_name = #name
.packet_type = (packet_tag)
.item_size = payload_member_size
.queue_buffer = name##_queue_buffer
.queue_struct = {0}
.queue = NULLThis is helpful for two reasons:
task_nameis automatic
The task name becomes the same as the symbol (handler config itself) name, which keeps config definitions compact and readable.- Queue internals are initialized consistently
The queue control structure is zero-initialized, and the runtime queue handle starts asNULL, matching the expectations of the dispatcher startup code.
IMPORTANT NOTE on payload_member
The payload_member argument is not the packet type name. It is the member name inside PBEnvelope.payload!
This matters because the macros compute size using direct member access syntax: sizeof( ((PBEnvelope*)0) -> payload.payload_member). So, if the wrong member name is used, compilation will fail, which is actually helpful for once.
The member names are defined in envelope.pb.h .
For example, currently envelope.pb.h contains the following:
typedef struct _PBEnvelope {
pb_size_t which_payload;
union _PBEnvelope_payload {
/* Sensorboard messages */
SensorBoardPHInfo ph_info;
/* Armboard messages */
ArmBoardControlSignals arm_ctrl;
ArmBoardDiagnostics arm_diag;
//etc etc...
}
}So, the macro must be called with the member name matching the rest of the config, such as ph_info or arm_ctrl and NOT the protobuf struct type name!
Available macros
1) Default configuration macros
The header defines these default values:
#define PACKET_HANDLER_DEFAULT_PRIORITY (tskIDLE_PRIORITY + 2U)
#define PACKET_HANDLER_DEFAULT_QUEUE_LENGTH (5U)
#define PACKET_HANDLER_DEFAULT_STACK_DEPTH (0U)PACKET_HANDLER_DEFAULT_PRIORITY
Default FreeRTOS task priority assigned to handler tasks created with the simpler macros.PACKET_HANDLER_DEFAULT_QUEUE_LENGTH
Default number of queued packets per handler.PACKET_HANDLER_DEFAULT_STACK_DEPTH
Default stack depth field stored in the config.
A value of0Uis intentional here. In the dispatcher implementation, a task stack depth of zero is treated as “use the dispatcher default,” which becomes:PACKET_HANDLER_TASK_STACK_DEPTH_DEFAULT. So this macro does not mean “zero stack.” It means “defer to the runtime default chosen by the dispatcher.”
2) Basic config: PACKET_HANDLER_CONFIG_STATIC
#define PACKET_HANDLER_CONFIG_STATIC(name, packet_tag, payload_member_size, handler_fn)This is the simplest form. Creates a handler config using:
- default priority
- default queue length
- default stack depth behaviour
Parameters
name
User defined name, go crazy.packet_tag
This is the Nanopb generated tag for the packet type. They follow the patternPBEnvelope_[payload_member]_tag. So for example: PBEnvelope_arm_ctrl_tagpayload_member
See important note on payload_member. Needs to match the packet_tag and the buffer type the callback is specified for!handler_fn
Callback function. Type signature packet_handler_t.
Example
/* Config for: ArmBoardMovementFeedback */
//Define the callback function with the specified signature
static result_t Callback_ArmBoardMovementFeedback(void *buffer) {
if (buffer == NULL) {
return RESULT_ERR_INVALID_ARG;
}
//Retreive the packet
ArmBoardMovementFeedback* pckt = (ArmBoardMovementFeedback *)buffer;
//Get all fields
pckt->arm_error;
/*
Go wild...
*/
return RESULT_OK;
}
PACKET_HANDLER_CONFIG_STATIC(
Handler_ArmBoardMovementFeedback, // NOTE: This name is USER DEFINED, let your imagination run
PBEnvelope_arm_feedback_tag, // Make sure these...
arm_feedback, // ... MATCH!
Callback_ArmBoardMovementFeedback); // Callback as above3) Full config: PACKET_HANDLER_CONFIG_STATIC_EX
#define PACKET_HANDLER_CONFIG_STATIC_EX(name, packet_tag, payload_member, handler_fn,
priority_, stack_depth_, queue_length_)Full explicit version. Lets you set:
- name, packet_tag, payload_member, handler_fn as above
- custom priority
- custom stack depth
- custom queue length
Best used when
- the handler needs a non-default stack size
- you want fully explicit resource configuration
Example
PACKET_HANDLER_CONFIG_STATIC_EX(vision_handler_cfg,
PBEnvelope_detected_object_tag,
detected_object,
handle_detected_object,
tskIDLE_PRIORITY + 3U,
768U,
16U);these r not in the code lol
begin here
II) PACKET_HANDLER_CONFIG_STATIC_QUEUE
#define PACKET_HANDLER_CONFIG_STATIC_QUEUE(name, packet_tag, payload_member_size, handler_fn, queue_length_)Same as the basic macro, but lets you override queue length.
Best used when
- handler needs a longer or shorter queue
- default priority is still fine
Example
PACKET_HANDLER_CONFIG_STATIC_QUEUE(sensor_handler_cfg,
PBEnvelope_sensor_diag_tag,
sensor_diag,
handle_sensor_diag,
12);III) PACKET_HANDLER_CONFIG_STATIC_PRIO
#define PACKET_HANDLER_CONFIG_STATIC_PRIO(name, packet_tag, payload_member, handler_fn, priority_)Same as the basic macro, but lets you override task priority.
Best used when
- one handler must run at a different RTOS priority
- default queue length is still fine
Example
PACKET_HANDLER_CONFIG_STATIC_PRIO(emergency_handler_cfg,
PBEnvelope_arm_obstructions_tag,
arm_obstructions,
handle_arm_obstructions,
tskIDLE_PRIORITY + 4U);IV) PACKET_HANDLER_CONFIG_STATIC_PRIO_QUEUE
#define PACKET_HANDLER_CONFIG_STATIC_PRIO_QUEUE( name, packet_tag, payload_member, handler_fn, queue_length_, priority_)Lets you override both:
- queue length
- task priority
Best used when
- a handler has non-default scheduling needs
- and also non-default backlog requirements
Example
PACKET_HANDLER_CONFIG_STATIC_PRIO_QUEUE(nav_handler_cfg,
PBEnvelope_ph_info_tag,
ph_info,
handle_ph_info,
10,
tskIDLE_PRIORITY + 3U);end here
Recommended Usage Pattern
More information on the mentioned steps can be found in Functions of the Packet Dispatcher
Typical Usage Model
Intended setup
- Define one handler function per packet type
- define one packet_handler_config_t entry per packet type (using the macros)
- provide queue storage buffers
(When using the macros, you do not need to do this manually) - call PacketDispatcherInit(...)
- whenever a frame arrives, call DispatchPacket()
Flow after setup
- Ethernet/UDP receives raw frame
- networking code builds
receive_frame DispatchPacket()decodes it- payload type is matched
- decoded payload is copied into target queue
- matching handler task wakes
- the callback processes typed payload
IMPORTANT configuration rules
This module is heavily configuration-driven. Several things must match exactly.
I. packet_type must match the protobuf discriminator
Each handler’s packet_type must be the exact value used by PBEnvelope.which_payload. If this is wrong, packets will never reach that handler.
II. item_size must match the decoded payload type
The queue copies bytes from &DecodingEnvelopeCurrent.payload into a queue item of size item_size.
If item_size is:
- too small -> payload will be truncated
- too large -> copied data may include unrelated union bytes or layout assumptions
- wrong type entirely -> handler sees garbage with confidence
III. queue_buffer must be sized correctly
The backing storage must be at least: queue_length * item_size. If not, queue creation or runtime behavior is invalid.
IV. Handler must cast void * correctly
The callback receives a raw buffer pointer. It must cast to the correct generated protobuf type.
V. Handlers array must be an array of structs
The current PacketDispatcherInit() API expects:
packet_handler_config_t* handlersmeaning a contiguous array of structs, not an array of pointers.
So with the current implementation, the final array should actually be:
static packet_handler_config_t* handlers[] = {
drive_handler_cfg,
sensor_diag_handler_cfg,
};NOT an array of pointers.
Examples
1) Using macros
//Imports
#include "packet_dispatcher.h"
#include "packet_dispatcher_macros.h"
/*Define handler callbacks*/
//Callback for protobuf of type ArmBoardMovementFeedback
static result_t Callback_ArmBoardMovementFeedback(void *buffer) {
if (buffer == NULL) {
return RESULT_ERR_INVALID_ARG;
}
ArmBoardMovementFeedback* pckt = (ArmBoardMovementFeedback *)buffer; //Retreive the packet
pckt->arm_error; //Get fields of protobuf
//Do something...
return RESULT_OK;
}
//Config using most basic macro
PACKET_HANDLER_CONFIG_STATIC(Handler_ArmBoardMovementFeedback, PBEnvelope_arm_feedback_tag, arm_feedback, Callback_ArmBoardMovementFeedback);
//Callback for protobuf of type ArmBoardControlSignals
static result_t Callback_ArmBoardControlSignals(void *buffer) {
if (buffer == NULL) {
return RESULT_ERR_INVALID_ARG;
}
ArmBoardControlSignals* pckt = (ArmBoardControlSignals *)buffer;
pckt->control_base; //Get fields of protobuf
pckt->control_gripper_pitch;
//... etc etc
//Do something...
return RESULT_OK;
}
//Config using most basic macro
PACKET_HANDLER_CONFIG_STATIC(Handler_ArmBoardControlSignals, PBEnvelope_arm_ctrl_tag, arm_ctrl, Callback_ArmBoardControlSignals);
//Add configs to the list of configs
static packet_handler_config_t* handlers[] = {Handler_ArmBoardMovementFeedback, Handler_ArmBoardControlSignals};
//HERE WE PUT ETH_init(...) and the creation of queues from the networking board
//See respective documentation
PacketDispatcherInit(handlers, 2);
ETH_udp_init(2, queues, DispatchPacket); //Passing DispatchPacket to ETH_udp_init makes sure it gets called upon receiving msgs
//Once again, after this we can use networking and do ETH_add_arp(...) and ETH_udp_send(...)2) Manual configuration
//Imports
#include "packet_dispatcher.h"
static result_t handle_drive_cmd(void* buffer) {
PBDriveCommand* msg = (PBDriveCommand*)buffer;
return drive_process(msg);
}
static result_t handle_arm_cmd(void* buffer) {
PBArmCommand* msg = (PBArmCommand*)buffer;
return arm_process(msg);
}
static uint8_t drive_queue_storage[8 * sizeof(PBDriveCommand)];
static uint8_t arm_queue_storage[4 * sizeof(PBArmCommand)];
static packet_handler_config_t handlers[] = {
{
.handler = handle_drive_cmd,
.task_name = "drive_pkt",
.packet_type = PBEnvelope_drive_cmd_tag,
.task_priority = 3,
.task_stack_depth = 512,
.item_size = sizeof(PBDriveCommand),
.queue_length = 8,
.queue_buffer = drive_queue_storage,
},
{
.handler = handle_arm_cmd,
.task_name = "arm_pkt",
.packet_type = PBEnvelope_arm_cmd_tag,
.task_priority = 3,
.task_stack_depth = 512,
.item_size = sizeof(PBArmCommand),
.queue_length = 4,
.queue_buffer = arm_queue_storage,
},
};Then during startup:
result_t res = PacketDispatcherInit(handlers, ARRAY_LEN(handlers));And during frame reception:
DispatchPacket(&rx_frame);Embedded Common Libraries
All Common Libraries used by all Microcontrollers in the Rover
Overview
This page gives a high-level overview of the shared libraries described so far, what each one is for, how they fit together, and how they are meant to be used in the codebase.
The goal is not to replace the detailed documentation for each module.
These libraries are all small, but they are not random utilities. Together they form a set of shared infrastructure for building embedded application code that is:
- more consistent
- easier to reason about
- easier to extend
- less likely to devolve into every subsystem inventing its own incompatible habits
Which, naturally, is what happens the moment shared infrastructure is missing.
Design philosophy of the shared library layer
Before going into the individual libraries, it helps to understand the common design pattern behind them.
These libraries are not trying to be a giant framework. They are trying to provide targeted, reusable building blocks for recurring embedded problems:
- reporting success and failure consistently
- logging runtime behavior in a uniform way
- storing shared variable-sized state in a controlled memory region
- scheduling work by discrete priority
- decoding and dispatching incoming protocol messages to the correct subsystem
The philosophy behind them is mostly this:
Centralize recurring patterns
If every module invents its own result codes, logging style, queueing scheme, and packet dispatching logic, the system becomes harder to maintain very quickly.
These libraries centralize those patterns so the rest of the application can focus on subsystem logic instead of re-solving the same infrastructure problems over and over.
Keep APIs small and practical
The libraries generally expose narrow APIs with very specific purposes.
Prefer explicit ownership and caller-provided resources
Several of these modules rely on the caller to provide memory, configuration, or queue storage.
That is not accidental. It keeps ownership visible and lets the application control where resources live.
Separate policy from mechanism where useful
A few libraries expose a generic interface while allowing board-specific or implementation-specific backends.
Examples:
- the logging API is conceptually transport-agnostic even though the current implementation uses UART
- the packet dispatcher API is conceptually about routing decoded packets even though the current implementation uses FreeRTOS queues and tasks
- the KV pool lets callers decide where metadata and storage memory live
Be honest about constraints
These are embedded libraries and we are not that good at coding.
A lot of their usefulness depends on respecting their assumptions:
- some are single-consumer by design
- some are not ISR-safe
- some assume static lifetime of configuration objects
- some have concurrency limitations that matter a lot
That is why documentation matters here. These modules are only “simple” if you already know their rules.
How the libraries fit together
At a system level, the libraries can be thought of as falling into a few categories.
Core utility infrastructure
These are foundational and broadly reusable:
resultlogging
They define how modules report status and how the system reports runtime information.
Storage and local scheduling infrastructure
These are reusable building blocks for internal system behavior:
bucketed_pqueuekv_pool
They solve internal resource management and work scheduling problems.
Communication and protocol infrastructure
These are more application-flow oriented:
- packet dispatcher / decoding task
- packet dispatcher macros
They take incoming protocol messages and move them to the right processing logic.
A good mental model is:
resultdefines how functions communicate success and failureloggingdefines how the system communicates information outwardbucketed_pqueuedefines how work can be prioritized internallykv_pooldefines how variable-sized keyed data can be stored safely in managed memory- the dispatcher layer defines how external messages enter the application and get routed to the correct handlers
Result Library
Purpose
The result module defines a shared result code system for the codebase.
Its job is to give functions a consistent way to report success and failure without inventing random local conventions like:
0means success here1means success there- negative values somewhere else
- and one cursed module returning
truefor failure because someone was feeling creative
Instead, functions return a result_t, which makes error handling:
- consistent
- readable
- easier to propagate upward
- easier to log
- easier to document
This module also provides:
- string conversion helpers for result codes
- helper macros for early-return error propagation
- optional logging-aware propagation macros when the logging module is included
What files belong to this module
This module consists of:
result.hresult.c
result.h
Defines:
- the
result_tenum - the public string conversion functions
- the helper macros:
TRYTRY_CLEANTRY_LOGTRY_LOG_CLEAN
result.c
Implements:
result_to_short_str()result_to_desc_str()
What problem this solves
In an embedded system, functions fail for many reasons:
- invalid arguments
- timeouts
- communication issues
- bad packet formats
- state machine misuse
- lack of memory
- busy resources
- and the usual parade of avoidable pain
That gives the codebase several benefits:
- function contracts are clearer
- errors can be passed up the call chain without translation
- logs can use the same human-readable error text
- helper macros reduce repetitive boilerplate
Core design
The design is intentionally simple:
RESULT_OKmeans success- every other
result_tvalue represents a failure or exceptional condition - functions return a single enum value
- callers decide whether to:
- handle the error locally
- return it upward
- clean up before returning
- log it before returning
This makes result_t a lightweight, shared error protocol.
Public API overview
The public API consists of:
result_tresult_to_short_str()result_to_desc_str()TRY(expr)TRY_CLEAN(expr)TRY_LOG(expr)TRY_LOG_CLEAN(expr)
String conversion functions
The module provides two functions for converting result codes into human-readable text.
These are useful for:
- logs
- diagnostics
- debug output
- CLI or terminal status messages
- test failure reporting
result_to_short_str()
const char *result_to_short_str(result_t code);Purpose
Returns a short label for a result code.
Examples
RESULT_OK->"OK"RESULT_ERR_TIMEOUT->"Timeout"RESULT_ERR_INVALID_ARG->"Invalid Argument"
Default behavior
If the result code is unknown or unsupported, it returns:
"Unknown Error"Intended use
This is best for compact output such as:
ERROR: Timeout
ERROR: Invalid Packet
ERROR: Buffer too smallresult_to_desc_str()
const char *result_to_desc_str(result_t code);Purpose
Returns a longer descriptive explanation of a result code.
Examples
RESULT_OK->"The operation completed successfully."RESULT_ERR_TIMEOUT->"An operation failed to complete within the allotted time."RESULT_ERR_INVALID_ARG->"A provided argument is null, out of range, or otherwise invalid."
Default behavior
If the code is unknown or unsupported, it returns:
"An unknown error code was encountered."Intended use
This is useful when more context is needed, especially in logs:
Invalid Argument: A provided argument is null, out of range, or otherwise invalid.Important implementation detail: mapping must stay synchronized
The enum in result.h and the switch statements in result.c must stay synchronized.
At the moment, they are not fully synchronized.
Why this matters
This causes:
- misleading logs
- incomplete diagnostics
- confusion for anyone trying to use those result codes
Maintenance rule
Whenever a new result_t value is added, both conversion functions must be updated in the same change.
This should be treated as mandatory.
Error propagation macros
The module provides a set of helper macros that reduce repetitive boilerplate when working with result_t.
These macros assume the common pattern:
- call a function returning
result_t - if it failed, stop current flow
- either return immediately or jump to cleanup
TRY(expr)
#define TRY(expr) \
do { \
result_t _try_status = (expr); \
if (_try_status != RESULT_OK) { \
return _try_status; \
} \
} while (0)Purpose
Evaluates an expression returning result_t.
If the result is not RESULT_OK, the current function immediately returns that result.
Example
result_t motor_start(void) {
TRY(motor_check_ready());
TRY(motor_enable_power());
TRY(motor_configure_pwm());
return RESULT_OK;
}Expanded behavior
This behaves roughly like:
result_t status = motor_check_ready();
if (status != RESULT_OK) {
return status;
}for each call.
When to use it
Use TRY() when:
- the current function also returns
result_t - no local cleanup is needed before returning
- you want simple upward propagation
TRY_CLEAN(expr)
#define TRY_CLEAN(expr) \
do { \
result_t _try_status = (expr); \
if (_try_status != RESULT_OK) { \
goto cleanup; \
} \
} while (0)Purpose
Evaluates an expression returning result_t.
If the result is not RESULT_OK, execution jumps to a cleanup: label.
Example
result_t process_frame(void) {
result_t status = RESULT_OK;
void *buffer = NULL;
buffer = malloc(128);
if (buffer == NULL) {
return RESULT_ERR_NO_MEM;
}
TRY_CLEAN(step_one());
TRY_CLEAN(step_two());
TRY_CLEAN(step_three());
return RESULT_OK;
cleanup:
free(buffer);
return RESULT_ERR;
}TRY_LOG(expr)
When LOGGING_H is defined, this macro becomes:
#define TRY_LOG(expr) \
do { \
result_t _try_status = (expr); \
if (_try_status != RESULT_OK) { \
LOGE(TAG, "%s: %s", result_to_short_str(_try_status), \
result_to_desc_str(_try_status)); \
return _try_status; \
} \
} while (0)Purpose
Like TRY(), but also emits a log message before returning.
Required assumption
The surrounding scope must define TAG, because the macro calls:
LOGE(TAG, ...)If TAG is not defined, compilation will fail.
Example
#define TAG "NET"
result_t net_start(void) {
TRY_LOG(net_hw_init());
TRY_LOG(net_link_up());
return RESULT_OK;
}If net_link_up() returns RESULT_ERR_TIMEOUT, the log might look like:
[ERROR] NET: Timeout: An operation failed to complete within the allotted time.and then the function returns that result.
TRY_LOG_CLEAN(expr)
When LOGGING_H is defined, this macro becomes:
#define TRY_LOG_CLEAN(expr) \
do { \
result_t _try_status = (expr); \
if (_try_status != RESULT_OK) { \
LOGE(TAG, "%s: %s", result_to_short_str(_try_status), \
result_to_desc_str(_try_status)); \
goto cleanup; \
} \
} while (0)Purpose
Like TRY_CLEAN(), but logs before jumping to cleanup.
Behavior when logging is not available
The logging-aware macros depend on whether LOGGING_H is defined.
This means they behave differently depending on whether the logging header has been included before result.h.
That is an important design detail.
When LOGGING_H is defined
If the logging header has already been included, TRY_LOG and TRY_LOG_CLEAN perform logging through LOGE.
This couples the macros to the logging module without hard-including it from result.h.
That keeps result.h lightweight, but also makes behavior depend on include order.
When LOGGING_H is not defined
The code falls back to compiler-specific warning behavior.
GCC / Clang
The macros emit a compile-time warning via _Pragma(...) and then degrade to:
TRY(expr)TRY_CLEAN(expr)
MSVC
They emit a compiler message and also degrade to the non-logging versions.
Other compilers
A general #warning is emitted and the macros degrade to the non-logging versions.
Practical meaning
If logging is not available, the macros still work for flow control. They just do not log.
Recommended usage guidelines
Prefer specific result codes
Use the most precise result_t value that matches the failure.
Prefer:
RESULT_ERR_INVALID_ARGRESULT_ERR_TIMEOUTRESULT_ERR_NOT_INITIALIZED
over generic:
RESULT_FAIL
when possible.
Keep RESULT_FAIL as fallback only
RESULT_FAIL should mean:
“something failed, but no existing specific code fits cleanly.”
It should not become the default.
Use TRY() only in functions returning result_t
Otherwise the generated return _try_status; is wrong.
Use TRY_CLEAN() only when a cleanup label exists
And only when you understand whether the error code is preserved.
Define TAG before using logging-aware macros
Without it, TRY_LOG and TRY_LOG_CLEAN are not valid.
Keep conversion functions updated
Whenever a new enum value is added, update:
result_to_short_str()result_to_desc_str()
in the same commit.
This should be treated as mandatory maintenance.
Suggested mental model
Think of this module as:
“The project-wide language for function outcomes.”
It is not just a list of enum values.
It defines how modules communicate success and failure to each other, and the helper macros define the common patterns for passing those outcomes upward through the call stack.
That makes it foundational infrastructure, even if the code itself is small and visually innocent.
Logging
Purpose
The logging library provides a simple UART-based logging interface for embedded firmware.
Its main job is to let the application print formatted log messages such as:
[INFO] MOTOR: Initialization complete
[WARNING] SENSOR: Value out of range: 8123
[ERROR] CAN: Failed to transmit frameThe module is intentionally small:
- it supports three log levels
- it formats messages in a consistent style
- it sends all output over a single UART
- it provides convenience macros for compile-time log filtering
This is a printf-style logging system, not a structured logger, ring buffer, or asynchronous trace system.
What problem this solves
Without this module, code would need to:
- manually format strings
- manually select a UART
- manually prepend log level tags
- duplicate formatting logic across the project
This library centralizes that behavior so all logs:
- use the same format
- use the same transport
- can be filtered by log level at compile time
- remain easy to call from application code
Output format
Every log produced by LOG() is formatted as:
[LEVEL] TAG: message\r\nExample
LOG(LOG_INFO, "IMU", "Sensor ready");produces:
[INFO] IMU: Sensor ready\r\nAnother example:
LOG(LOG_ERROR, "ETH", "TX failed with code %d", err);produces something like:
[ERROR] ETH: TX failed with code -3\r\nComponents
A log line contains:
- opening bracket
[ - level string such as
INFO - closing bracket and space
] - tag string
- separator
: - user message string
- CRLF line ending
\r\n
The line ending is Windows/terminal friendly and also common for UART console output.
Public API overview
The public interface consists of:
LogLevellog_level_to_string()LOG_init()LOG()- convenience macros:
LOGELOGWLOGI
Log levels
Enum definition
typedef enum {
LOG_INFO,
LOG_WARNING,
LOG_ERROR,
_LOG_LAST_LEVEL_DONT_EDIT
} LogLevel;Meaning
The library supports three levels:
LOG_INFOLOG_WARNINGLOG_ERROR
These are stored as enum values starting at 0.
The final enum value:
_LOG_LAST_LEVEL_DONT_EDITis not an actual log level. It is a sentinel used to:
- count how many log levels exist
- validate the string table size
Why that sentinel exists
The library keeps a parallel array of strings:
static const char *LOG_LEVEL_STRINGS[] = {
"INFO",
"WARNING",
"ERROR",
};The enum and string table must stay aligned.
The sentinel lets the code verify that automatically with static_assert.
log_level_to_string()
static inline const char *log_level_to_string(LogLevel logLevel);Purpose
Converts a LogLevel enum into its corresponding string.
Valid conversions
LOG_INFO->"INFO"LOG_WARNING->"WARNING"LOG_ERROR->"ERROR"
If the value is outside the valid range, it returns:
"NoLevel"Notes
This function is declared static inline in the header, so each translation unit including the header gets its own inline copy.
It also contains a compile-time check:
static_assert((sizeof(LOG_LEVEL_STRINGS) / sizeof(LOG_LEVEL_STRINGS[0])) ==
_LOG_LAST_LEVEL_DONT_EDIT,
"Mismatch in number of log level strings!");This prevents someone from adding or removing enum levels without updating the string table.
That is one of the few parts of this module behaving like it has trust issues, which is correct.
Backend independence of the API
Although the current implementation sends logs over UART, the public API itself is not inherently UART-specific.
From the perspective of code using the logger, the interface is simply:
- initialize the logging system with
LOG_init(...) - emit logs with
LOG(...) - or use the convenience macros
LOGI,LOGW, andLOGE
Nothing in normal application code needs to know how the log is actually transported.
What this means in practice
The current board-specific implementation uses:
- a UART handle passed into
LOG_init() HAL_UART_Transmit()for output_write()retargeting for stdout
But that is only one possible backend.
A different board or firmware target could keep the same header/API and provide a different implementation, for example:
- USB CDC logging
- SWO / ITM logging
- RTT logging
- CAN or Ethernet debug output
- buffered logging to memory
- semihosting during development
Why this matters
This separation means the API should be understood as a logical logging interface, not as a UART contract.
In this codebase, each board can provide its own implementation behind the same header, as long as it preserves the expected external behavior of the API.
That makes the module portable across boards without forcing higher-level application code to care about the physical logging transport, which is one of the few times abstraction is actually doing something useful instead of just breeding paperwork.
Maintenance guidance
If a future board needs a different logging transport, the preferred approach is:
- keep
logging.hstable if possible - replace or adapt the implementation file for that board
- preserve the meaning of:
LOG_init()LOG()LOGI/LOGW/LOGE
This allows application code to remain unchanged while the backend changes per target.
Initialization
LOG_init()
void LOG_init(void *arg);Purpose
Initializes the logging system by providing the UART handle that will be used for all later output.
Expected argument
arg must point to a valid UART_HandleTypeDef.
In practice:
LOG_init(&huart2);or whichever UART handle should be used for logging.
What it does internally
LOG_init() performs these steps:
- Casts
argstoUART_HandleTypeDef - copies the pointed-to UART handle into a private static variable
- sets an internal
initializedflag - writes a boot banner directly using
_write() - emits an info log saying logging was initialized
Important requirements
LOG_init() must be called before any normal logging is expected to work.
If LOG() is called before initialization, it silently returns without output.
Main logging function
LOG()
void LOG(LogLevel level, const char *TAG, const char *log_message, ...);Purpose
Formats and transmits a log line over UART.
Parameters
level
The severity level of the message.
Expected values:
LOG_INFOLOG_WARNINGLOG_ERROR
If the value is invalid, the implementation falls back to:
"UNKNOWN"for formatting.
TAG
A short text label identifying the source of the log.
Typical examples:
"IMU""CAN""DISPATCHER""ETH"
This appears in the formatted output after the log level.
log_message
A printf-style format string.
Examples:
"Init done""Received packet %u""Voltage too high: %d mV"
Optional variadic arguments used by the format string.
Example usage
LOG(LOG_INFO, "MOTOR", "Started with speed %u", speed);
LOG(LOG_WARNING, "TEMP", "High temperature: %d", temp);
LOG(LOG_ERROR, "FLASH", "Write failed");Behavior when not initialized
If logging has not been initialized yet, the function returns immediately:
if (initialized == 0) {
return;
}No output is produced.
This is deliberate.
Internal formatting process
The implementation builds the final message in two phases.
Phase 1: Build a full format string
It first constructs a format string like:
[INFO] MOTOR: Started with speed %u\r\nThis is stored in dynamically allocated memory called format_message.
Phase 2: Format variadic arguments into final output
It then uses vsnprintf() twice:
- once to calculate the final required length
- once to write the fully formatted message into another dynamically allocated buffer
That final message is transmitted using:
HAL_UART_Transmit(&huart_handler, (uint8_t *)total_message, total_len, HAL_MAX_DELAY);After transmission, both heap allocations are freed.
Retargeted _write()
int _write(int file, char *ptr, int len);Purpose
This function retargets standard output to the configured UART.
Behavior
If the file descriptor is 1:
if (file == 1)the function transmits the provided buffer over UART using HAL_UART_Transmit().
It then returns len.
Why this exists
On many embedded toolchains, overriding _write() allows C library output functions such as printf() to write to UART.
That means this module is not only a custom logging module. It also partially redirects stdout.
Important note
This implementation only handles file descriptor 1, which is typically stdout.
It does not distinguish stderr or other descriptors.
Interaction with LOG()
LOG() does not actually use printf() or _write() for its main output path. It calls HAL_UART_Transmit() directly after formatting its message.
LOG_init() does use _write() once to print the boot banner.
So _write() exists mainly for stdout retargeting and the boot line, not as the core mechanism used by LOG() itself.
Convenience macros
The header defines these macros:
LOGELOGWLOGI
These call LOG() with a fixed level, but only if that level is enabled by CONFIG_LOG_LEVEL.
Default log level configuration
If CONFIG_LOG_LEVEL is not defined by the build system, the header sets:
#define CONFIG_LOG_LEVEL LOG_INFOThis means all log levels are enabled by default.
Macro behavior
LOGE
#define LOGE(TAG, format, ...) LOG(LOG_ERROR, TAG, format, ##__VA_ARGS__)Enabled when:
(CONFIG_LOG_LEVEL <= LOG_ERROR)Because LOG_ERROR is the highest enum value in this setup, this macro is enabled for all current supported configurations.
LOGW
#define LOGW(TAG, format, ...) LOG(LOG_WARNING, TAG, format, ##__VA_ARGS__)Enabled when:
(CONFIG_LOG_LEVEL <= LOG_WARNING)LOGI
#define LOGI(TAG, format, ...) LOG(LOG_INFO, TAG, format, ##__VA_ARGS__)Enabled when:
(CONFIG_LOG_LEVEL <= LOG_INFO)Filtering semantics
Since the enum values are ordered:
LOG_INFO = 0LOG_WARNING = 1LOG_ERROR = 2
a lower configured value means more logs enabled.
Examples
CONFIG_LOG_LEVEL = LOG_INFO
Enabled:
- info
- warning
- error
CONFIG_LOG_LEVEL = LOG_WARNING
Enabled:
- warning
- error
Disabled:
- info
CONFIG_LOG_LEVEL = LOG_ERROR
Enabled:
- error only
Disabled:
- warning
- info
Disabled macro behavior
When disabled, the macro expands to:
(void)0So the call is compiled out.
This is compile-time filtering, not runtime filtering.
That matters because disabled log calls impose essentially no runtime cost.
Typical usage pattern
Initialization
At system startup, once the UART peripheral is ready:
LOG_init(&huart2);This should happen before any code that expects logging output.
Logging from application code
Use one of the convenience macros in normal code:
LOGI("NET", "Ethernet initialized");
LOGW("ADC", "Reading outside expected range: %u", sample);
LOGE("FLASH", "Erase failed at sector %u", sector);This is the intended public usage style.
Using LOG() directly is also valid when needed.
Tag conventions
The module does not enforce tag format, so the team should adopt a convention.
A good pattern is to use short subsystem names, such as:
"ETH""CAN""SCHED""MOTOR""UI""SENSOR"
Since this logger is plain text over UART, bloated tags just make the output harder to scan.
Priority Queue
Summary
bucketed_pqueue is a simple, efficient strict-priority queue for FreeRTOS systems where:
- items fall into a small fixed set of priority levels
- producers may be tasks or ISRs
- a single consumer drains work in priority order
Its design is intentionally lightweight:
- one FreeRTOS queue per priority
- one bitmap to track which priorities are active
- optional task notification for efficient wakeup
Used correctly, it is a clean fit for embedded event dispatch and deferred work handling.
Used incorrectly, mainly with multiple consumers or inconsistent bucket item types, it becomes a fine little trap with excellent timing and poor manners.
Purpose
The bucketed_pqueue module implements a strict-priority queue on top of standard FreeRTOS queues.
Instead of storing all items in one queue, it uses multiple FIFO queues, called buckets, where each bucket represents one priority level.
- Bucket 0 = lowest priority
- Bucket
num_buckets - 1= highest priority
When consuming items, the module always returns an item from the highest non-empty priority bucket.
Within the same priority bucket, ordering remains FIFO, because each bucket is an ordinary FreeRTOS queue.
This gives the system:
- strict priority across buckets
- FIFO ordering within each bucket
- support for task producers
- support for ISR producers
- a lightweight way to wake a consumer task when new work arrives
When to use this module
Use this module when:
- work items have a small fixed number of priority levels
- higher-priority items must always be processed first
- you want to keep FreeRTOS queue semantics
- producers may run in both task and interrupt context
- only one consumer is responsible for draining the queue
Typical use cases:
- event dispatching where alarms/errors must preempt normal work
- deferred interrupt processing with different urgency levels
- message handling where command classes have discrete priority bands
When to not use this module
This module is not a general-purpose concurrent priority queue.
Do not use it if:
- you need multiple consumer tasks calling
pop()orpeek()concurrently - you need arbitrary numeric priorities rather than a small fixed bucket range
- you need blocking pop behavior built into the module
- you need stable ordering across different priorities based on timestamp or insertion order
The implementation is designed around multiple producers, single consumer.
High-Level Design
The queue is made from:
- an array of FreeRTOS queue handles
- a count of how many buckets exist
- a 32-bit bitmap tracking which buckets are currently believed to be non-empty
- an optional task handle to notify when something is pushed
Core idea
Each priority level has its own FreeRTOS queue.
The module maintains a bitmap:
- bit
nset = bucketnis believed to contain at least one item - bit
nclear = bucketnis believed to be empty
This bitmap lets the consumer avoid blindly probing every queue all the time.
Example
If there are 4 buckets:
- bucket 0 = low
- bucket 1 = medium
- bucket 2 = high
- bucket 3 = critical
And the bitmap is:
non_empty_mask = 0b1010then bucket 1 and bucket 3 are non-empty.
A call to bucketed_pqueue_pop() will check from highest to lowest, so it will try:
- bucket 3
- bucket 2
- bucket 1
- bucket 0
and return the first available item it finds.
Data Structure
typedef struct {
QueueHandle_t *buckets;
uint8_t num_buckets;
uint32_t non_empty_mask;
TaskHandle_t notifier;
} bucketed_pqueue_t;Fields
buckets
Pointer to an array of QueueHandle_t.
Each entry is a FreeRTOS queue representing one priority bucket.
This array is not owned by the module. The caller must create the queues and ensure the array remains valid for the entire lifetime of the priority queue.
num_buckets
Number of buckets in the buckets array.
Valid range: 1 to 32.
The upper limit exists because non_empty_mask is a 32-bit bitmap.
non_empty_mask
Bitmap used as a fast summary of which buckets contain items.
- bit
0corresponds to bucket0 - bit
1corresponds to bucket1 - etc.
This bitmap is updated on push, and cleared when the consumer determines a bucket is empty.
notifier
Optional task to notify when an item is successfully pushed.
If not NULL, a push sets the notification bit:
1UL << prioin the target task’s notification value.
This is useful when the consumer task waits on task notifications instead of polling.
Important behavioral guarantees
This module provides the following behavior:
Strict priority
Higher-priority buckets are always preferred over lower-priority buckets.
If bucket 3 and bucket 1 both contain items, pop() will always return from bucket 3 first.
FIFO within one priority
Because each bucket is a FreeRTOS queue, items in the same bucket are processed in insertion order.
Non-blocking pop/peek
pop() and peek() do not wait. If no item is available, they return RESULT_ERR_NOT_FOUND.
Multi-context producers
There are separate APIs for:
- task context:
bucketed_pqueue_push() - ISR context:
bucketed_pqueue_push_from_isr()
Single-consumer design
The implementation assumes only one consumer performs pop() and peek().
That is not just a suggestion. It is a design constraint.
Required setup
This module does not create FreeRTOS queues itself.
The caller must:
- create one FreeRTOS queue for each priority level
- store those queue handles in an array
- initialize a
bucketed_pqueue_tusing that array
Example setup
#define NUM_BUCKETS 4
static QueueHandle_t bucket_handles[NUM_BUCKETS];
bucketed_pqueue_t pq;
void app_init(void) {
bucket_handles[0] = xQueueCreate(8, sizeof(my_msg_t));
bucket_handles[1] = xQueueCreate(8, sizeof(my_msg_t));
bucket_handles[2] = xQueueCreate(8, sizeof(my_msg_t));
bucket_handles[3] = xQueueCreate(8, sizeof(my_msg_t));
bucketed_pqueue_init(&pq, bucket_handles, NUM_BUCKETS, consumer_task_handle);
}Strong recommendation
All buckets should use the same item type or at least size.
Technically the module does not enforce that. Practically, mixing queue item sizes makes the API awkward and error-prone, because pop() and peek() write into a single out buffer and the caller has no type information at that point.
Usage model
Producer side
A producer decides the priority and pushes into the matching bucket.
Example:
my_msg_t msg = { ... };
bucketed_pqueue_push(&pq, PRIORITY_HIGH, &msg, pdMS_TO_TICKS(10));From an ISR:
BaseType_t higher_woken = pdFALSE;
my_msg_t msg = { ... };
bucketed_pqueue_push_from_isr(&pq, PRIORITY_HIGH, &msg, &higher_woken);
portYIELD_FROM_ISR(higher_woken);Consumer side
The consumer repeatedly pops the highest-priority item available.
Example:
my_msg_t msg;
while (bucketed_pqueue_pop(&pq, &msg) == RESULT_OK) {
process_msg(&msg);
}Because pop() is non-blocking, a typical design is:
- consumer task blocks on a task notification
- on wakeup, it calls
pop()in a loop untilRESULT_ERR_NOT_FOUND
Example pattern:
for (;;) {
uint32_t notified_bits = 0;
xTaskNotifyWait(0, UINT32_MAX, ¬ified_bits, portMAX_DELAY);
my_msg_t msg;
while (bucketed_pqueue_pop(&pq, &msg) == RESULT_OK) {
process_msg(&msg);
}
}This pattern works well with the module’s notifier mechanism.
Notification behavior
If notifier is provided during initialization, every successful push sends a task notification with:
1UL << priousing eSetBits.
This means:
- pushes do not overwrite previous notification bits
- multiple buckets can be represented in the task notification value
- repeated pushes to the same priority keep the same bit set
What the notification means
The notification indicates that at least one push occurred into that bucket.
It does not guarantee:
- how many items are in that bucket
- that the bucket is still non-empty by the time the task wakes
- that the bitmap and queues are perfectly synchronized at all times
It is a wakeup hint, not a count.
That is fine. The consumer should drain the queue with repeated pop() calls rather than assuming one notification equals one item.
Concurrency model and assumptions
This section matters more than the function list.
Supported access pattern
Supported
- multiple producer tasks
- ISR producers
- one consumer task calling
pop()and/orpeek()
Not supported
- multiple concurrent consumers calling
pop() - one task peeking while another task pops in a way that assumes strong synchronization guarantees
- external code modifying the underlying bucket queues directly behind this module’s back
The module uses a bitmap plus queue operations, but it does not implement a full multi-consumer synchronization scheme around dequeue behavior.
Why single-consumer matters
The bitmap is read, scanned, and repaired in steps.
That is acceptable with one consumer, because any race is limited to producer updates and queue state changes, and the consumer can repair stale bits safely.
With multiple consumers, two tasks could:
- observe the same bitmap snapshot
- both decide the same bucket has data
- one drains the queue
- the other sees an empty queue and clears the bit
That alone is survivable, but once multiple consumers are simultaneously probing and repairing, reasoning about ordering and fairness gets messy fast. This module avoids that entire circus by assuming a single consumer.
Critical sections
The bitmap is protected with FreeRTOS critical sections:
taskENTER_CRITICAL()/taskEXIT_CRITICAL()taskENTER_CRITICAL_FROM_ISR()/taskEXIT_CRITICAL_FROM_ISR()
These critical sections protect bitmap access, not the whole queue operation sequence.
That means queue operations and bitmap updates are not one indivisible transaction.
This is intentional and mostly fine for the intended model, but maintainers should understand that the bitmap is a best-effort summary, not a perfect mirror of queue state.
Known implementation characteristics
Priority scan is linear in number of buckets
pop() and peek() scan from highest to lowest priority:
for (int prio = num_buckets - 1; prio >= 0; prio--)So the dequeue cost is O(num_buckets) in the worst case.
Since num_buckets <= 32, this is usually acceptable in embedded systems.
If someone later decides to turn this into 128 priorities with a 32-bit bitmap, you might want to consider a better scanning system for all buckets.
That said, the loop is incredibly efficient doing only a bit-wise check to know if the bucket is populated or not.
Bitmap may be temporarily stale
The module can have these transient states:
- queue contains data but bitmap not yet updated
- bitmap says non-empty but queue is empty
The code handles the second case explicitly by clearing stale bits when xQueueReceive() or xQueuePeek() fails.
The first case is shorter-lived and happens between a successful queue send and the bitmap update, or if initialization starts with pre-filled queues.
This is why the bitmap should be viewed as a hint structure.
No ownership of queue storage
The module does not allocate or destroy the bucket queues.
It only stores the queue handles provided by the caller.
The caller is responsible for:
- creating queues before initialization
- keeping them alive while the priority queue is in use
- ensuring item types and queue lengths are appropriate
No reset/deinit API
There is no deinitialization function.
If needed, the caller must manage queue lifecycle itself.
If a reset feature is ever added, it must consider:
- draining or recreating each bucket
- resetting
non_empty_mask - possible interaction with producers still running
Practical example
Scenario
A system has three priorities:
0: telemetry1: commands2: emergency actions
All use the same message type:
typedef struct {
uint8_t type;
uint32_t value;
} app_msg_t;Setup
#define APP_NUM_PRIORITIES 3
static QueueHandle_t app_buckets[APP_NUM_PRIORITIES];
static bucketed_pqueue_t app_pq;
void app_queue_init(TaskHandle_t consumer_task) {
app_buckets[0] = xQueueCreate(16, sizeof(app_msg_t));
app_buckets[1] = xQueueCreate(16, sizeof(app_msg_t));
app_buckets[2] = xQueueCreate(8, sizeof(app_msg_t));
bucketed_pqueue_init(&app_pq, app_buckets, APP_NUM_PRIORITIES, consumer_task);
}Producer task
void send_command(uint32_t cmd) {
app_msg_t msg = {
.type = 1,
.value = cmd,
};
(void)bucketed_pqueue_push(&app_pq, 1, &msg, 0);
}ISR producer
void emergency_isr(void) {
BaseType_t higher_woken = pdFALSE;
app_msg_t msg = {
.type = 2,
.value = 0xDEADU,
};
(void)bucketed_pqueue_push_from_isr(&app_pq, 2, &msg, &higher_woken);
portYIELD_FROM_ISR(higher_woken);
}Consumer task
void consumer_task(void *arg) {
(void)arg;
for (;;) {
uint32_t notify_bits;
xTaskNotifyWait(0, UINT32_MAX, ¬ify_bits, portMAX_DELAY);
app_msg_t msg;
while (bucketed_pqueue_pop(&app_pq, &msg) == RESULT_OK) {
handle_message(&msg);
}
}
}Result
If telemetry, commands, and emergency messages all arrive, the consumer will process:
- emergency
- commands
- telemetry
Within each class, messages remain FIFO.
Error handling
The module uses result_t, which is defined elsewhere.
Based on the implementation, these results are used:
RESULT_OK
Operation succeeded.
RESULT_ERR_INVALID_ARG
Returned when the caller passes invalid arguments, such as null pointers or out-of-range priority.
RESULT_ERR_OVERFLOW
Returned by push functions when the selected bucket queue cannot accept the item.
This usually means the bucket queue is full, or the send timed out.
RESULT_ERR_NOT_FOUND
Returned by pop() or peek() when no item is available.
This is not necessarily an error in the usual sense. It is the normal result for an empty priority queue.
Maintenance notes
If you change the number of buckets beyond 32
You must also change:
- the bitmap type
- all bit shift logic
- input validation
- notification assumptions based on
1UL << prio
Right now, 32 buckets is a hard architectural limit.
If you add blocking pop behavior
Be careful.
A naive implementation that blocks on each bucket in order would break strict priority or become awkward and expensive.
A better approach is usually to keep the existing design:
- producers notify a task
- consumer waits on notification
- consumer drains with non-blocking
pop()
If you still add a blocking API, document its wakeup semantics very clearly.
If you want multiple consumers
This requires redesign.
You would need to revisit:
- bitmap synchronization
- dequeue race handling
- semantics of
peek() - fairness between consumers
- whether the notifier model still makes sense
Do not label it “thread-safe” just because critical sections exist.
If different buckets need different item types
The current API is not a good fit for that.
pop() and peek() return into one generic out buffer with no explicit type metadata.
If you need heterogeneous payloads, safer patterns are:
- use a tagged union message type
- store pointers to separately managed objects
- wrap payloads in a common envelope struct
If queues are pre-filled before init
The bitmap starts at zero during bucketed_pqueue_init().
So pre-filled queues will not be visible until something later sets the relevant bits, or until code is changed to rebuild the bitmap.
If supporting pre-filled queues matters, one possible improvement is for init() to inspect each bucket using uxQueueMessagesWaiting() and initialize non_empty_mask accordingly.
That behavior does not exist today.
Key-Value Pool
Purpose
The kv_pool module implements a fixed-key key-value store backed by a custom memory pool.
It is designed for systems where:
- keys are known as integer indices in a fixed range
- values are variable-sized blobs of bytes
- dynamic allocation from the general heap is undesirable or unavailable
- memory must come from a caller-provided region
- multiple threads may access the store concurrently
The module combines two things:
- a lookup table that maps keys to stored values
- an internal heap allocator that manages the memory used by those values
The result is a storage system where each key corresponds to one slot, and each valid slot points to a block allocated from the pool’s private heap.
This is not a dictionary in the desktop-software sense. Keys are not hashed, compared, or discovered dynamically. A key is just an index into a preallocated slot table.
What problem this solves
This module exists to store variable-sized values in a memory-constrained system without relying on the standard heap.
It solves these problems:
- fixed set of logical keys, but variable-sized data per key
- need to provide memory externally
- need to safely read and update values across threads
- need to reclaim storage when a key is removed
- need predictable ownership of all stored data
Instead of calling malloc() and free() from the general runtime allocator, the module manages a private heap inside caller-provided memory.
That gives the application explicit control over:
- where memory lives
- how large the pool is
- how many keys exist
- whether metadata and data live together or in different memory regions
High-Level Design
The module consists of two main parts.
Lookup table
Each key corresponds to one kv_slot.
A slot contains:
- a per-slot lock
- a pointer to the stored data block
- the size of that block
- a validity flag
If a slot is valid, the key currently has stored data.
If a slot is invalid, the key is empty.
Internal heap
Actual data bytes are stored inside a custom heap managed by the module.
This heap:
- lives in caller-provided memory
- uses a free-list allocator
- allocates variable-sized blocks
- coalesces adjacent free blocks when freeing
This means the slot table stores metadata only. The actual value bytes are stored elsewhere in the pool heap.
Memory model
The pool manages two logical memory regions:
- lookup table memory
- data heap memory
These can be provided in two ways:
Contiguous mode
One big memory block is given to kv_pool_init(). The module splits it into:
- lookup table
- data heap
Fragmented mode
Separate memory regions are given to kv_pool_init_fragmented(). This allows the lookup table and data heap to live in different memory banks.
That can be useful when, for example:
- metadata should live in fast SRAM
- bulk value storage should live in larger but slower RAM
Public API overview
The public API consists of:
- data structures:
kv_slotkv_headerkv_pool
- macros:
KV_ALIGNMENTALIGN(x)MINIMUM_BLOCK_SIZELOOKUP_TABLE_SIZE(x)
- initialization:
kv_pool_init_fragmented()kv_pool_init()
- key operations:
kv_pool_get()kv_pool_write()kv_pool_insert()kv_pool_remove()kv_pool_is_index_valid()
- allocator functions:
kv_pool_allocate()kv_pool_free()
The last two are currently exposed in the header, although they behave more like internal allocator primitives than ordinary user-facing API.
Data structures
kv_slot
typedef struct {
atomic_flag slot_lock;
void *data_ptr;
size_t data_size;
bool is_valid;
} kv_slot;Purpose
Represents the metadata for one key.
Fields
slot_lock
A spinlock protecting this slot’s metadata and associated data access.
Used to synchronize operations on a single key.
data_ptr
Pointer to the allocated data block in the internal heap.
The caller must not free or reallocate this pointer directly.
data_size
Size in bytes of the stored value.
is_valid
Whether this slot currently contains valid data.
If false, the key is considered empty.
Important note
The key itself is not stored in the slot. The key is simply the slot’s index in the lookup table.
kv_header
typedef struct kv_header {
size_t size;
union {
struct kv_header *next_free;
char data[1];
} as;
} kv_header;Purpose
Header for blocks in the internal heap.
Role
When a block is free, as.next_free links it into the free list.
When a block is allocated, as.data is the start of the user-visible payload.
Meaning of size
size is the total size of the block, including the header and payload region.
This is important for:
- pointer arithmetic
- block splitting
- coalescing adjacent free blocks
kv_pool
typedef struct {
void *pool_start;
size_t pool_size;
atomic_flag heap_lock;
void (*delay)(void);
kv_header *free_list_head;
size_t max_keys;
kv_slot *lookup_table;
} kv_pool;Purpose
Represents the entire key-value pool.
Fields
pool_start
Start address of the data heap region.
pool_size
Size of the data heap region in bytes.
heap_lock
Spinlock protecting heap allocator operations.
delay
Callback invoked while waiting for a lock.
This is used during busy-waiting to avoid a pure tight spin.
free_list_head
Head of the free-list allocator.
max_keys
Maximum number of keys supported by this pool.
Valid keys are:
0 <= key < max_keyslookup_table
Pointer to the slot array.
Alignment and size macros
KV_ALIGNMENT
#define KV_ALIGNMENT 16All allocations are aligned to this boundary.
This affects:
- payload placement
- allocator block sizes
- pointer arithmetic
If this value changes, allocator behavior changes with it.
ALIGN(x)
#define ALIGN(x) (((x) + (KV_ALIGNMENT - 1)) & ~(KV_ALIGNMENT - 1))Rounds a size up to the next KV_ALIGNMENT boundary.
Used by the allocator.
MINIMUM_BLOCK_SIZE
#define MINIMUM_BLOCK_SIZE sizeof(kv_header) + 1Minimum block size allowed in the heap.
Used to decide whether a free block can be split.
The allocator will not create a leftover free fragment smaller than this.
LOOKUP_TABLE_SIZE(x)
#define LOOKUP_TABLE_SIZE(x) (sizeof(kv_slot) * (x))Returns the number of bytes required for a lookup table supporting x keys.
Used during initialization and memory size validation.
Initialization APIs
kv_pool_init_fragmented()
result_t kv_pool_init_fragmented(void *lookup_table,
size_t lookup_table_size,
size_t max_keys,
void *pool_data,
size_t pool_size,
kv_pool *pool,
void (*delay)(void));Purpose
Initializes a pool from two separate memory regions:
- one for slot metadata
- one for heap storage
Parameters
lookup_table
Memory for the kv_slot array.
lookup_table_size
Size of the lookup table memory region in bytes.
max_keys
Maximum number of keys.
pool_data
Memory for the heap region.
pool_size
Size of the heap region in bytes.
pool
Output pool structure to initialize.
delay
Function called while waiting for spinlocks.
Returns
RESULT_OKon successRESULT_ERR_INVALID_ARGif required pointers are null ormax_keys == 0RESULT_ERR_BUFFER_TOO_SMALLif:- heap is too small
- lookup table region is too small
What it does
- validates inputs
- clears both memory regions with
memset - sets up the lookup table
- sets up the free-list heap as one large free block
- clears locks
- marks all slots invalid
Important lifetime rule
The memory regions provided to this function must remain valid for the entire lifetime of the pool.
The module does not copy them.
kv_pool_init()
result_t kv_pool_init(void *data,
size_t data_size,
size_t max_keys,
kv_pool *pool,
void (*delay)(void));Purpose
Initializes a pool from one contiguous memory block.
Parameters
data
Start of the full memory region.
data_size
Total size of the region.
max_keys
Number of keys.
pool
Output pool structure.
delay
Lock wait callback.
Returns
RESULT_OKon successRESULT_ERR_BUFFER_TOO_SMALLif total memory is insufficient- any error returned by
kv_pool_init_fragmented()
What it does
It computes:
- lookup table size =
LOOKUP_TABLE_SIZE(max_keys) - heap start =
data + LOOKUP_TABLE_SIZE(max_keys) - heap size = remaining bytes
Then it delegates to kv_pool_init_fragmented().
When to use it
Use this function when you want simple setup from one static buffer.
Use kv_pool_init_fragmented() when memory placement matters.
Key operations
kv_pool_get()
result_t kv_pool_get(kv_pool *pool, int key, void *buffer, size_t *buffer_size);Purpose
Copies the value for a key into a caller-provided buffer.
Parameters
pool
Initialized pool.
key
Key index to read.
buffer
Destination buffer for copied data.
buffer_size
Input/output parameter.
- on input: capacity of
buffer - on output:
- actual copied size on success
- required size if buffer is too small
Returns
RESULT_OKon successRESULT_ERR_INVALID_ARGifpool == NULLorbuffer_size == NULLRESULT_ERR_NOT_FOUNDif key is out of range or not validRESULT_ERR_BUFFER_TOO_SMALLif destination buffer is too small
Behavior
The function:
- validates inputs
- checks key bounds
- locks the slot
- verifies the slot is valid
- checks whether the provided buffer is large enough
- copies the stored data with
memcpy - unlocks the slot
Important note
The function does not require buffer to be non-null when the buffer is too small path is taken first, but in practice a null buffer with a large enough buffer_size would lead to invalid memcpy. So callers should always provide a valid buffer unless they intentionally use this as a size query pattern and know what they are doing.
The implementation does not explicitly validate buffer != NULL. Why? No clue.
kv_pool_write()
result_t kv_pool_write(kv_pool *pool, int key, void *buffer, size_t buffer_size);Purpose
Overwrites the existing value for a valid key without reallocating memory.
Parameters
pool
Initialized pool.
key
Key index to overwrite.
buffer
Source data to copy from.
buffer_size
Size of new data.
Returns
RESULT_OKon successRESULT_ERR_INVALID_ARGifpool == NULL,buffer == NULL, or size mismatches existing allocationRESULT_ERR_NOT_FOUNDif key is invalid or not currently in use
Behavior
The function:
- validates arguments
- checks that the key refers to a valid existing slot
- locks the slot
- checks that
buffer_sizeexactly matches the stored size - copies new bytes over existing allocation
- unlocks the slot
Important constraint
This function does not resize.
The size must exactly match the existing allocation.
If the caller wants to store a different-sized value, they must:
- remove the key
- insert again with the new size
or implement a resize API in the future.
kv_pool_insert()
result_t kv_pool_insert(kv_pool *pool, int key, void *data, size_t data_size);Purpose
Allocates heap space and stores new data for a key.
Parameters
pool
Initialized pool.
key
Key index to populate.
data
Source bytes to copy into pool storage.
data_size
Size of the data to store.
Returns
Actual implementation returns:
RESULT_OKon successRESULT_ERR_INVALID_ARGif:pool == NULLdata == NULL- key is out of range
RESULT_ERR_NO_MEMif allocation fails
Inserting on an already allocated slot
If kv_pool_insert() is called on a slot that is already valid, the old allocation is orphaned and leaked from the pool heap.
So the safe usage rule today is:
- only call
kv_pool_insert()on an empty key - remove existing keys first before reinserting
The implementation does not enforce that, but callers must.
Internal behavior
The function:
- validates inputs
- locks the slot
- marks the slot invalid and clears metadata
- allocates a heap block
- copies data into the new block
- marks the slot valid
- unlocks and returns
kv_pool_remove()
result_t kv_pool_remove(kv_pool *pool, int key);Purpose
Removes a key and frees its allocated data block.
Parameters
pool
Initialized pool.
key
Key index to remove.
Returns
Actual implementation returns:
RESULT_OKon successRESULT_ERR_INVALID_ARGifpool == NULLRESULT_ERR_NOT_FOUNDif key is out of bounds or not valid
Behavior
The function:
- validates the pool pointer
- verifies the key is valid with
kv_pool_is_index_valid() - calls
kv_pool_free()on the stored pointer
kv_pool_is_index_valid()
result_t kv_pool_is_index_valid(kv_pool *pool, int key);Purpose
Checks whether a key currently contains valid data.
Parameters
pool
Initialized pool.
key
Key index to check.
Returns
RESULT_OKif key is in range and validRESULT_ERR_INVALID_ARGif pool is null or key is out of rangeRESULT_ERR_NOT_FOUNDif slot is currently invalid
Behavior
The function:
- validates arguments
- locks the slot
- checks
is_valid - unlocks and returns a snapshot result
Important concurrency note
This is only a snapshot.
A slot that is valid at the time of the check may become invalid immediately afterward.
So callers must not do:
kv_pool_is_index_valid()- assume later access is now guaranteed safe forever
They must still handle failure from the actual operation.
Allocator APIs
These are declared in the header and can be called externally, but they behave like internal heap primitives.
Using them directly requires understanding the allocator and slot ownership rules.
kv_pool_allocate()
result_t kv_pool_allocate(kv_pool *pool, size_t size, void **out_ptr);Purpose
Allocates a block from the pool heap.
Parameters
pool
Initialized pool.
size
Payload size requested.
out_ptr
Output pointer for the allocated payload address.
Returns
RESULT_OKon successRESULT_ERR_INVALID_ARGfor null pointers or zero sizeRESULT_ERR_NO_MEMif no free block can satisfy the request
Allocation strategy
The allocator uses first fit on the free list.
It scans from the head until it finds the first block large enough.
Block sizing
The allocator computes:
- header offset to payload
- total required size including header
- alignment rounding
- minimum block size enforcement
Splitting
If the selected block is larger than needed and the remainder is big enough, it splits the block and leaves the remainder on the free list.
Otherwise it consumes the whole block.
kv_pool_free()
result_t kv_pool_free(kv_pool *pool, void *ptr);Purpose
Returns a previously allocated block to the pool heap.
Parameters
pool
Initialized pool.
ptr
Pointer previously returned by kv_pool_allocate() or stored in a slot.
Returns
RESULT_OKon successRESULT_ERR_INVALID_ARGif arguments are null
Behavior
The function:
- derives the block header from the payload pointer
- inserts the block back into the sorted free list
- coalesces with adjacent free neighbors when possible
- scans the slot table for a matching
data_ptr - if found, clears that slot’s metadata
Important consequence
kv_pool_free() does not merely free heap memory. It also tries to invalidate any slot pointing at that memory.
That means allocator state and key-value metadata are coupled.
Safe usage implication
External callers should not casually use kv_pool_allocate() and kv_pool_free() unless they understand this coupling.
If you free a pointer that a slot still references, the function will clear that slot.
If you allocate memory manually and never attach it to a slot, the allocator still works, but you are now using the pool partly as a raw allocator and partly as a key-value store, which increases maintenance complexity.
Role of delay()
The caller supplies the delay function during pool initialization.
This allows board or environment-specific waiting behavior, such as:
- yielding
- sleeping
- short pause loop
- RTOS task delay
- platform-specific backoff
The pool does not define how delay behaves. That is the caller’s responsibility.
Example usage
Contiguous initialization
static uint8_t kv_memory[2048];
static kv_pool pool;
static void pool_delay(void) {
/* platform-specific wait/yield */
}
result_t app_kv_init(void) {
return kv_pool_init(kv_memory, sizeof(kv_memory), 16, &pool, pool_delay);
}This creates a pool with:
- 16 keys
- lookup table at the start of
kv_memory - heap in the remaining bytes
Insert value
uint32_t value = 1234;
result_t res = kv_pool_insert(&pool, 3, &value, sizeof(value));This stores 4 bytes at key 3.
Read value
uint32_t value = 0;
size_t size = sizeof(value);
result_t res = kv_pool_get(&pool, 3, &value, &size);On success:
res == RESULT_OKvaluecontains the stored bytessize == sizeof(uint32_t)
Handle too-small buffer
uint8_t small_buf[4];
size_t size = sizeof(small_buf);
result_t res = kv_pool_get(&pool, key, small_buf, &size);
if (res == RESULT_ERR_BUFFER_TOO_SMALL) {
/* size now contains required size */
}This is the intended size negotiation pattern.
Overwrite same-sized value
uint32_t new_value = 5678;
result_t res = kv_pool_write(&pool, 3, &new_value, sizeof(new_value));This succeeds only if key 3 already exists and has exactly 4 bytes allocated.
Remove key
result_t res = kv_pool_remove(&pool, 3);This frees the associated heap block and invalidates the slot.
Backend and platform independence
The API is largely independent of where memory comes from and how waiting is implemented.
The caller provides:
- raw memory regions
- a delay function
- the
kv_poolobject itself
That means different boards or environments can use the same API with different backing strategies, for example:
- contiguous static RAM region on one board
- split metadata/data regions across different RAM banks on another
- RTOS yield in the delay callback on one target
- busy-wait pause or test hook in host-side simulation
The implementation is therefore memory-placement agnostic and wait-strategy agnostic, even though the current source file provides one specific allocator and lock implementation.
This is useful for portability, provided each target respects the same concurrency and memory lifetime contract.
Recommended usage rules for current code
Given the implementation as it exists today, these rules are the safest:
- Initialize once before concurrent use.
- Provide memory that remains valid for the full pool lifetime.
- Use
insert()only on empty keys. - Use
write()only when new data size exactly matches old size. - Do not rely on
is_index_valid()as a guarantee for later access. - Treat direct allocator calls as advanced/internal use.
- Do not assume allocator concurrency is fully correct (there is definitely a bug or two in there).
- Always pass a valid destination buffer to
get()when copying data.
Unit Testing
Purpose
Unit tests in this repository are designed to validate component behavior, not entrypoint wiring.
- Tests target logic in
components/common/*andcomponents/<board>/*. src/<board>/main.cremains focused on initialization and task orchestration.- Test ownership mirrors component ownership: each component should have corresponding tests under
test/<owner>/.
Test stack
The project uses PlatformIO’s unit testing framework with Unity.
- Each test binary follows the Unity lifecycle:
UNITY_BEGIN()RUN_TEST(...)UNITY_END()
- Global Unity output configuration is provided via:
test/unity_config.htest/unity_config.c
- The current output implementation initializes UART and writes test output character-by-character over a COM interface.
Test layout
Tests are organized by ownership and module:
test/
├─ common/
│ ├─ test_bucketed_pqueue/
│ ├─ test_kv_pool/
├─ sensor_board/
│ ├─ test_gps_sensor/
│ ├─ test_imu_sensor/
│ ├─ test_ph_sensor/
│ ├─ test_sensor_basics/
├─ driving_board/
│ ├─ test_calculator/
│ ├─ test_motor/
├─ debugging_board/
│ ├─ test_input_handler/
├─ unity_config.c
└─ unity_config.hNaming conventions:
- Directory:
test/<owner>/test_<module>/ - File:
test_<behavior>.cortest_<module>.c - Function:
test_<expected_behavior>()
Running tests
Run all tests for a specific environment:
pio test -e sensor_boardRun all tests across all environments:
pio testRun a specific test directory:
pio test -e sensor_board -f test_imu_sensorEnvironment test selection (platformio.ini)
Test execution is controlled per environment using the test_filter setting.
Current configuration:
env:sensor_board→test_filter = sensor_board/*env:driving_board→test_filter = driving_board/*env:debugging_board→test_filter = common/*
When adding new tests, ensure the corresponding environment includes the test path in its test_filter. Otherwise, the tests will not be executed.
Writing a new unit test
1) Place it by ownership
Tests must follow the same ownership structure as the components.
Example:
- Component:
components/common/kv_pool - Test location:
test/common/test_kv_pool/
2) Use Unity structure
#include "unity.h"
void setUp(void) {}
void tearDown(void) {}
void test_example_behavior(void) {
TEST_ASSERT_TRUE(1);
}
int main(void) {
UNITY_BEGIN();
RUN_TEST(test_example_behavior);
return UNITY_END();
}3) Assert behavior, not implementation
- Use public APIs instead of accessing internal state directly.
- Cover both success and failure cases.
- Use precise assertions:
TEST_ASSERT_EQUALTEST_ASSERT_FLOAT_WITHIN- etc.
4) Keep tests deterministic
- Avoid reliance on shared or previous test state.
- Reset all required state in
setUp. - Use time-based operations only when necessary, and keep them bounded.
What to test
- Public functions in component modules
- Input validation and error handling
- Boundary conditions and invalid arguments
- State transitions and invariants
What not to test as unit tests
The following are outside the scope of unit testing:
- Full board startup flows in
main.c - End-to-end hardware integration
- Multi-component system orchestration
These belong to integration or system-level testing.
Troubleshooting
- No tests executed: verify
test_filterfor the selected environment (-e) - Test not detected: ensure correct directory naming (
test_<module>) undertest/ - No Unity output: check UART/COM configuration in
test/unity_config.cand board connection settings